Redesigning Critical Incident Management
Global Mining Leader, Reduced Downtime, Faster Resolutions, Enhanced Resilience



Executive Summary
In a global mining organisation, an inefficient and poorly structured Critical Incident Management process was prolonging outages and increasing operational risk. Incident broadcast miscommunications sent alerts to everyone regardless of relevance, unclear ownership arose from a technical component focus and underdeveloped IT services, while response delays stemmed from procedural confusion as support contractors often hesitated over steps like who to contact as the correct technical lead. Fatigue risks and loose vendor integration compounded the issues.
I led the redesign, bringing in accurate prioritisation and categorisation, targeted communication bridges, clear ownership tied to well defined services, streamlined procedures to remove hesitation points, proactive fatigue controls, and stronger vendor escalation paths. The transformed process delivered dramatically faster resolutions, precise and relevant communications, eliminated ownership disputes, and markedly stronger production resilience.
More importantly, the work exposed foundational gaps in data, ownership, and support structures. This directly sparked four follow-on projects. A full CMDB review, a service ownership and contact list overhaul, a technical distribution list cleanup, and a contractor playbook refresh. Although my role in those was limited to highlighting requirements and light-touch oversight, the incident management initiative provided the evidence and momentum needed to drive those essential changes.
The Challenge
- Inaccurate categorisation and prioritisation delaying effective triage and initial response
- Broadcast miscommunications flooding irrelevant stakeholders with alerts, creating noise and confusion
- Unclear ownership driven by a narrow technical component focus and underdeveloped IT services
- Procedural confusion causing response delays, with contractors hesitating over basic steps like identifying the correct technical lead to contact
- Unmanaged fatigue risks during prolonged incidents, impacting decision quality and team performance
- Loose vendor integration leading to slower escalations and detached support during critical events
The Solution
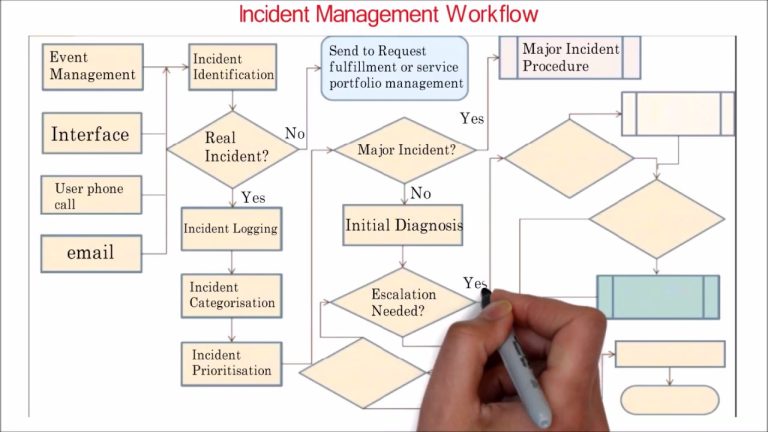
- Conducted a full system-wide diagnostic, blueprinting current workflows to pinpoint procedural gaps, communication failures, and ownership ambiguities
- Redesigned prioritisation and categorisation rules for accurate triage and faster initial response
- Built targeted communication bridges with smart distribution lists, ensuring alerts reached only relevant stakeholders without flooding others
- Established clear ownership mapping by aligning to well-defined IT services, eliminating technical-component silos and hesitation in hand-offs
- Streamlined procedures to remove confusion points, clarifying steps like technical lead contacts and mandatory checks for contractors
- Introduced proactive fatigue management controls, including shift limits and rotation triggers during prolonged incidents
- Strengthened vendor integration through defined escalation paths and joint accountability in critical events
- Delivered data-driven continuous improvement with simple metrics, regular reviews, and feedback loops to sustain gains
Results at a Glance
- Dramatically faster incident resolutions with significantly reduced production downtime
- Precise, relevant communications that eliminated alert noise and rebuilt stakeholder trust
- Clear ownership and swift hand-offs, removing hesitation and disputes during responses
- Proactive fatigue controls that protected team performance and decision-making in long-running incidents
- Tighter vendor integration delivering quicker escalations and more accountable external support
- Stronger overall production resilience and compliance through a dependable, embedded process
- Catalysed four foundational follow-on projects addressing CMDB accuracy, service ownership, distribution lists, and contractor playbooks
My Role & Insights
My Role:
I drove the full redesign of the Critical Incident Management process from initial diagnostic through to implementation and handover. I facilitated cross-functional workshops, mapped pain points against real incident examples, redesigned workflows and communication structures, defined clear ownership tied to services, and introduced practical controls for fatigue and vendors. I provided hands-on guidance during rollout, adjusted based on live feedback, and ensured the process was simple enough for teams to own long-term. My light-touch oversight also helped shape the four follow-on projects that emerged from the findings.
Key Insights
- Targeted communication beats blanket broadcasting every time, relevance restores trust quickly.
- Ownership problems almost always trace back to poorly defined services, fix the foundation and the rest follows.
- Procedural hesitation kills momentum in critical incidents, so every common decision point needs a clear default.
- Fatigue isn’t a side issue in prolonged events, build controls in from day one.
- A well run CIM improvement shines a light on wider data and governance gaps use that momentum rather than letting it fade.
© 2025 itservicemgmt.com. All rights reserved. Case studies and content are proprietary and confidential. Reproduction or distribution without written permission is prohibited